Reliably generating sequential IDs (i.e. numbers) is useful for a multitude of applications. For example, if you want to deliver messages asynchronously - say through a queue - and then reconstruct the message order on the receiving side.
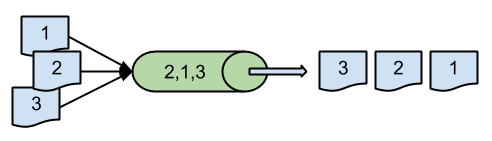 If you can be sure that the IDs 1, 2 and 3 were allocated in that order, it doesn't matter in what order they go through the queue, you can always sort them in the true order on the other side.
If you can be sure that the IDs 1, 2 and 3 were allocated in that order, it doesn't matter in what order they go through the queue, you can always sort them in the true order on the other side.
Conventional wisdom tells us that using an external component, especially a database, to generate application sequences is a bad idea. If you think about it, it makes sense right away - it's very hard to generate true sequential IDs in a distributed manner, and if it's not distributed then there will certainly be a hard upper limit to the number of items you can generate per time unit. In the context of Couchbase Server, we can use the increment operation to create a counter. Increment is atomic, so we can call it repeatedly from any number of treads or processes and be assured that it will return sequential values (assuming we actually pass a positive increment to the method.) If course, if we use a global counter to generate our sequence, it will be a single document, meaning it will reside on a single node. Regardless of how many nodes we actually have in the cluster, the processing load of incrementing the counter and saving it to disk will fall on that node alone. I wanted to find out just how bad this bottleneck would be: can I use a single counter for generating sequences globally in a distributed application with reasonable performance?
Test setup in Azure:
- Single-node Couchbase cluster on an A4 VM (8 cores, 14GB RAM, data on a RAID0 volume on top of 4 disks within the same affinity group.)
- Two application servers on similar A4 VMs:
- Python script calling
increment("counter", 1, 1)in a tight loop from multiple threads.
- Python script calling
- Only one document in the database - the counter itself, and no other load.

The first application server, at 100% CPU, managed about 25k increments per second. Bringing the second one online increased that to 40k.
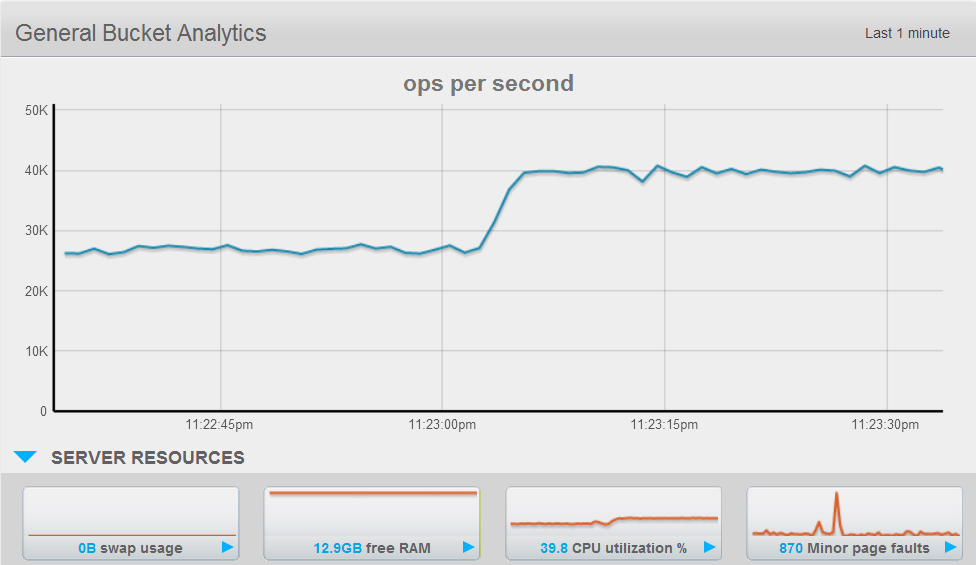
The database server steadied out at 40% CPU and essentially no disk activity. As you can see below, while the disk write queue fill rate was high, the actual number of disk writes was absurdly low, because Couchbase de-duplicates multiple updates to the same key before writing them to disk.
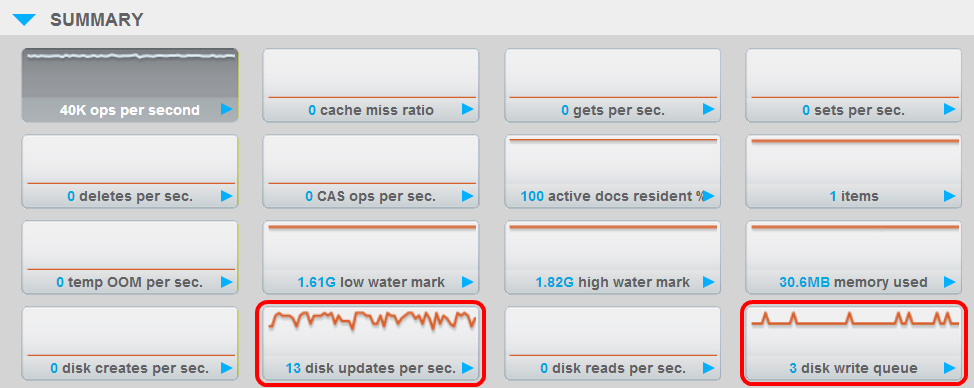
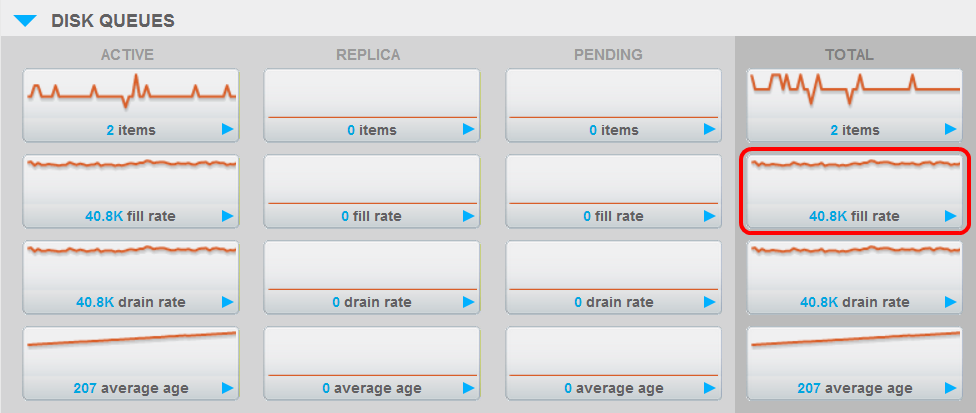
One thing you'll note is that the average age of the item(s) in the disk write queue is high and still rising. It's possible that Couchbase counts the age from the moment the counter item was first updated, since it never actually leaves the queue due to being constantly re-added.
In conclusion, we can see that even if we use one global counter for all our sequential IDs, we can still generate a respectable number of new items without overwhelming the node. Of course, if you need to generate sequential numbers at a higher rate, you shouldn't use a single global counter, as it will become a bottleneck at some point. One possibility is to use multiple counters, one per entity type, or application domain, or some other differentiator - to spread the load better.