TL;DR: The most compact printable ASCII encoding of a binary value is Ascii85 (aka. Base85). Encoding a 16-byte UUID as Base85 takes only 20 bytes, as opposed to 36 for the standard string representation.
Using UUIDs to generate unique keys for Couchbase documents is a popular choice. You can generate UUIDs on the client side without referring to some central component to provide unique values, they are widely supported and have a fairly familiar human-readable representation. However, UUID-based keys suffer from one important drawback - the standard string encoding is 36 bytes long: d8b594f4-bb26-49f8-bdc4-7d68aba9dc54. Since Couchbase keeps all document keys in memory, this can add up to a significant overhead for databases with a lot of documents. For example, a Couchbase bucket with one billion items would need 36 * 10^9 / 2^30 = 33.5 GB of RAM just to hold all the keys. If your documents are small, it's possible that you'll actually use more memory for keys than the documents themselves.
(Note: Couchbase Server 3.0, which is coming out soon, includes an optional feature to eject keys+metadata from memory along with their documents. This makes the key overhead a lot less of an issue. However, this feature negatively impacts the performance of some operations, so there are cases where you would not want to use it.)
Of course, we don't have to use the standard string UUID encoding. There are 95 printable ASCII characters, not including whitespace, so the most compact text encoding for a binary value is Ascii85 (aka. Base85), which encodes a 16-byte UUID as a 20-byte string, or only 25% more. Using the better known Base64 encoding takes 22 (or 24 with padding) bytes to represent a UUID, that is 33% more.
Because I'm lazy, I've used Jeff Atwood's C# implementation of Ascii85 to write a small demo application that inserts one million items with UUID-based keys into my Couchbase bucket, first using plain ToString() and then using Ascii85. You can download the solution here.
One million items with UUID.toString() as keys:
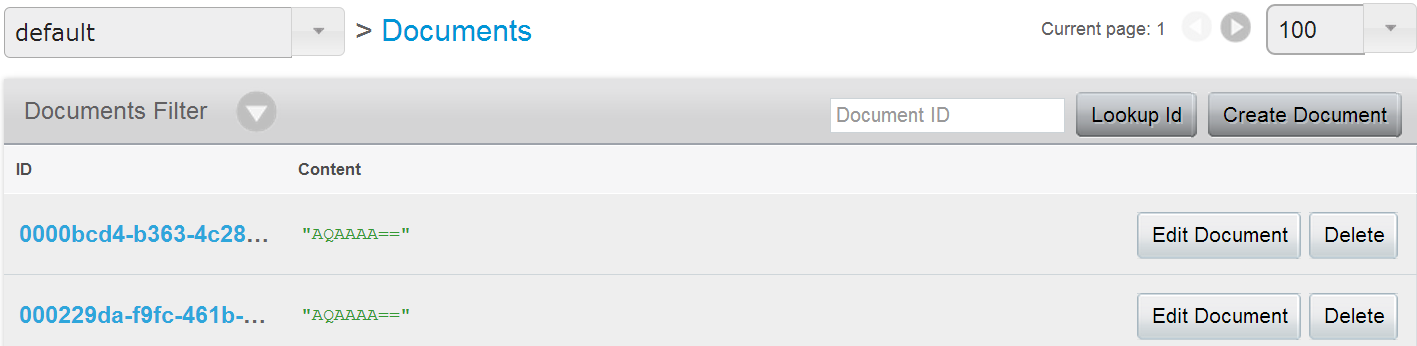
> cbstats localhost:11210 all | grep meta_data
ep_meta_data_memory: 92000000
Makes perfect sense, 92 bytes per item, 56 bytes metadata, 36 bytes key, which is exactly how much a plain string UUID representation with hyphens takes.
One million items with Base85 encoded UUIDs as keys:
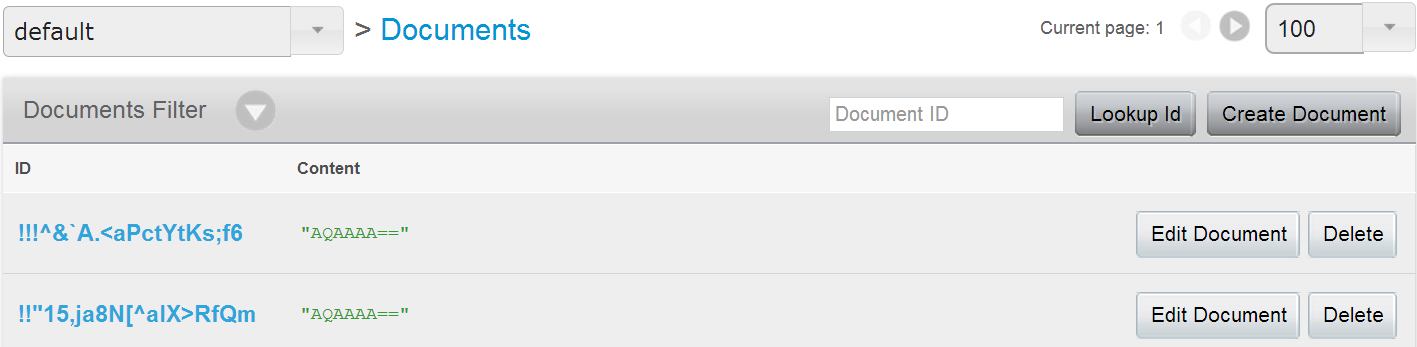
We do lose some readability with the Ascii85 encoded UUIDs. Hopefully you won't have to memorize them or anything.
> cbstats localhost:11210 all | grep meta_data
ep_meta_data_memory: 76000000
Just as expected, 76 bytes per item, 56 metadata, 20 bytes key.
As you can see, saving 16 bytes per key in a bucket with one million documents is no big deal, just 15 MB of RAM saved. However, saving 16 bytes per key in a bucket with one billion documents would be 15 GB of RAM saved, or rather used to cache document data for faster retrieval instead of storing long keys. Much better.
There are implementations of Base85 for several common languages. Alternatively, if you don't mind giving up 2 bytes per key, most modern frameworks come with a built-in implementation of Base64. Obviously, nothing comes for free - we pay for the memory saving with additional client-side CPU cycles to encode the keys at creation. Base64 is also somewhat faster than Base85; not that it matters a whole lot, since it's only used once per key.